Netty入门与实战:仿写微信 IM 即时通讯系统(一)
源码地址及更新日志
https://delaunay.coding.net/p/netty-demo/d/netty-demo/git
系统简介
Netty 是一个异步基于事件驱动的高性能网络通信框架,本文将利用Netty一步一步实现微信IM聊天的核心功能——单聊与群聊。
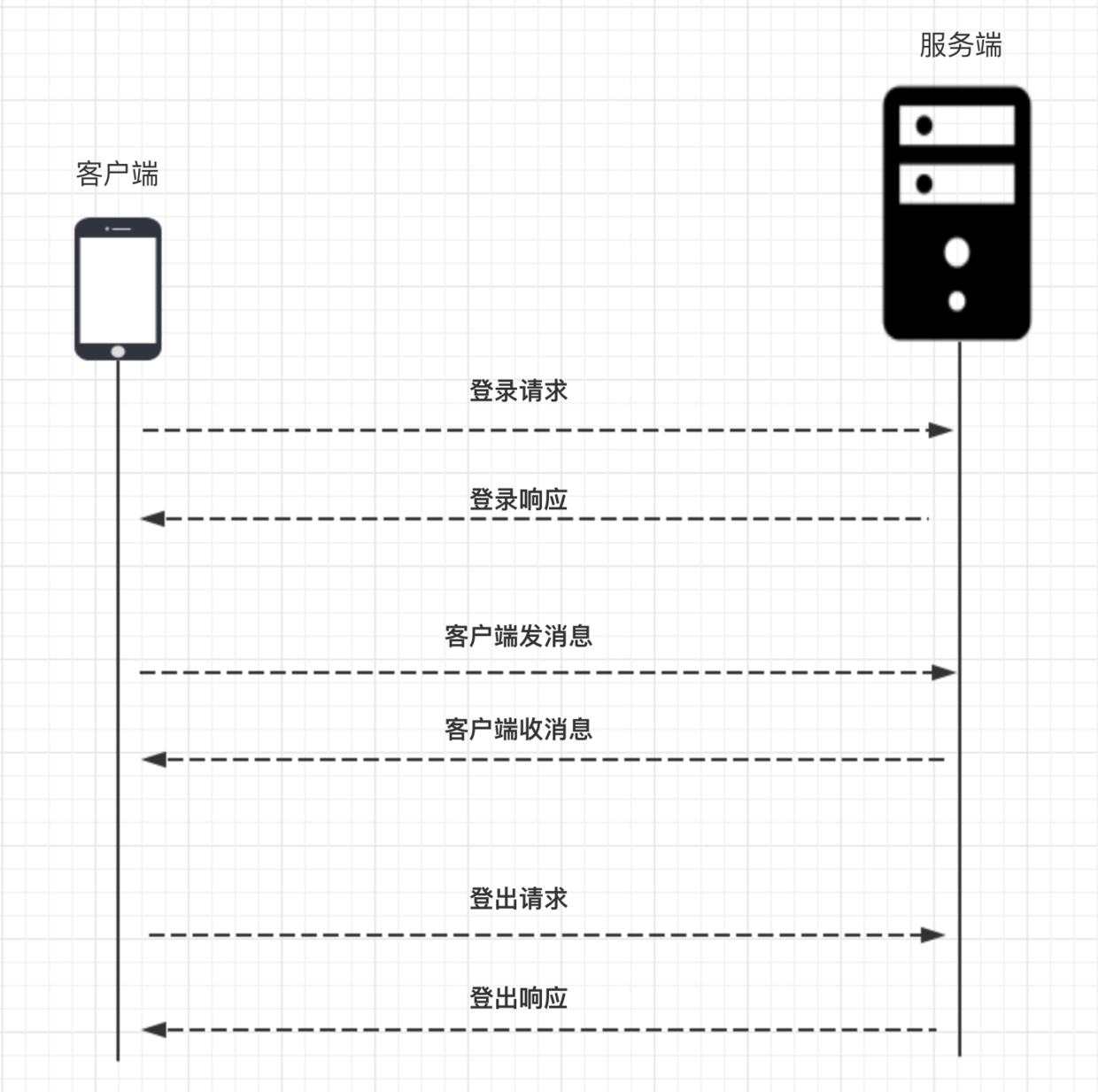
单聊
基本流程
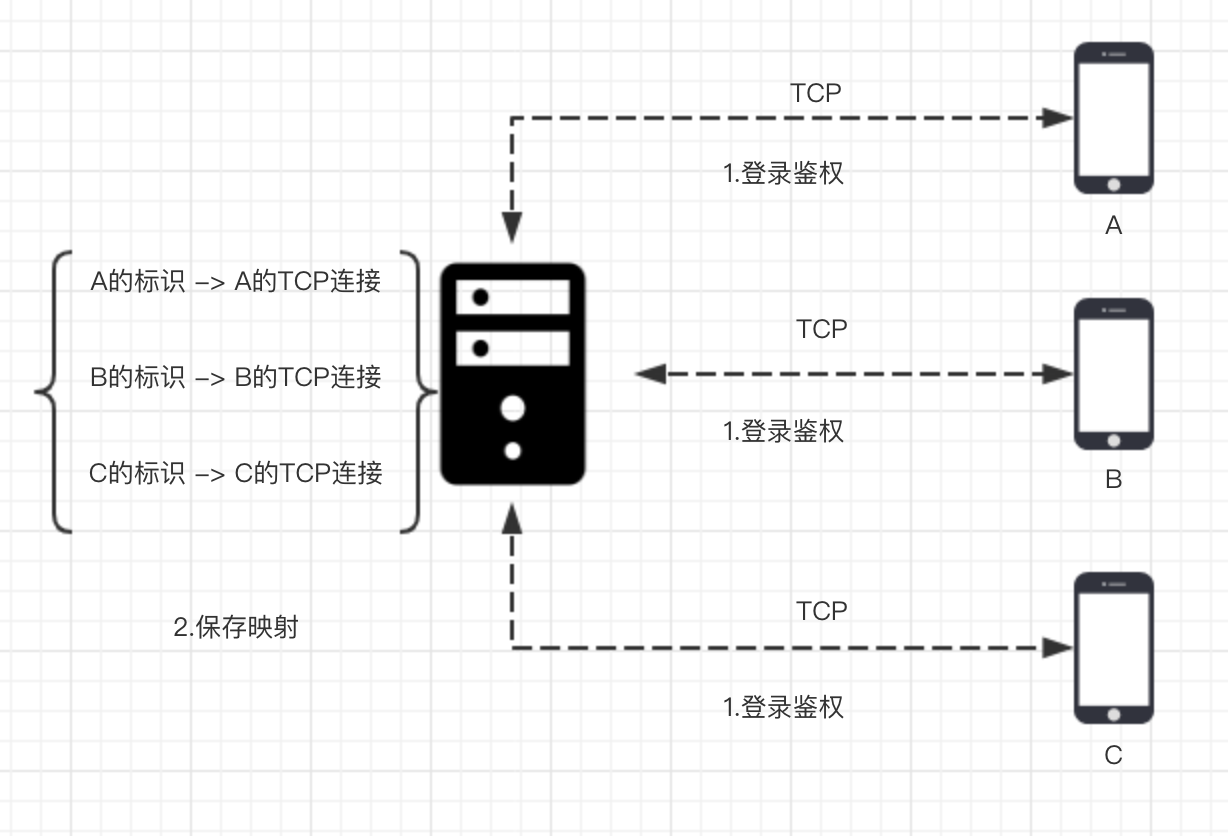
指令
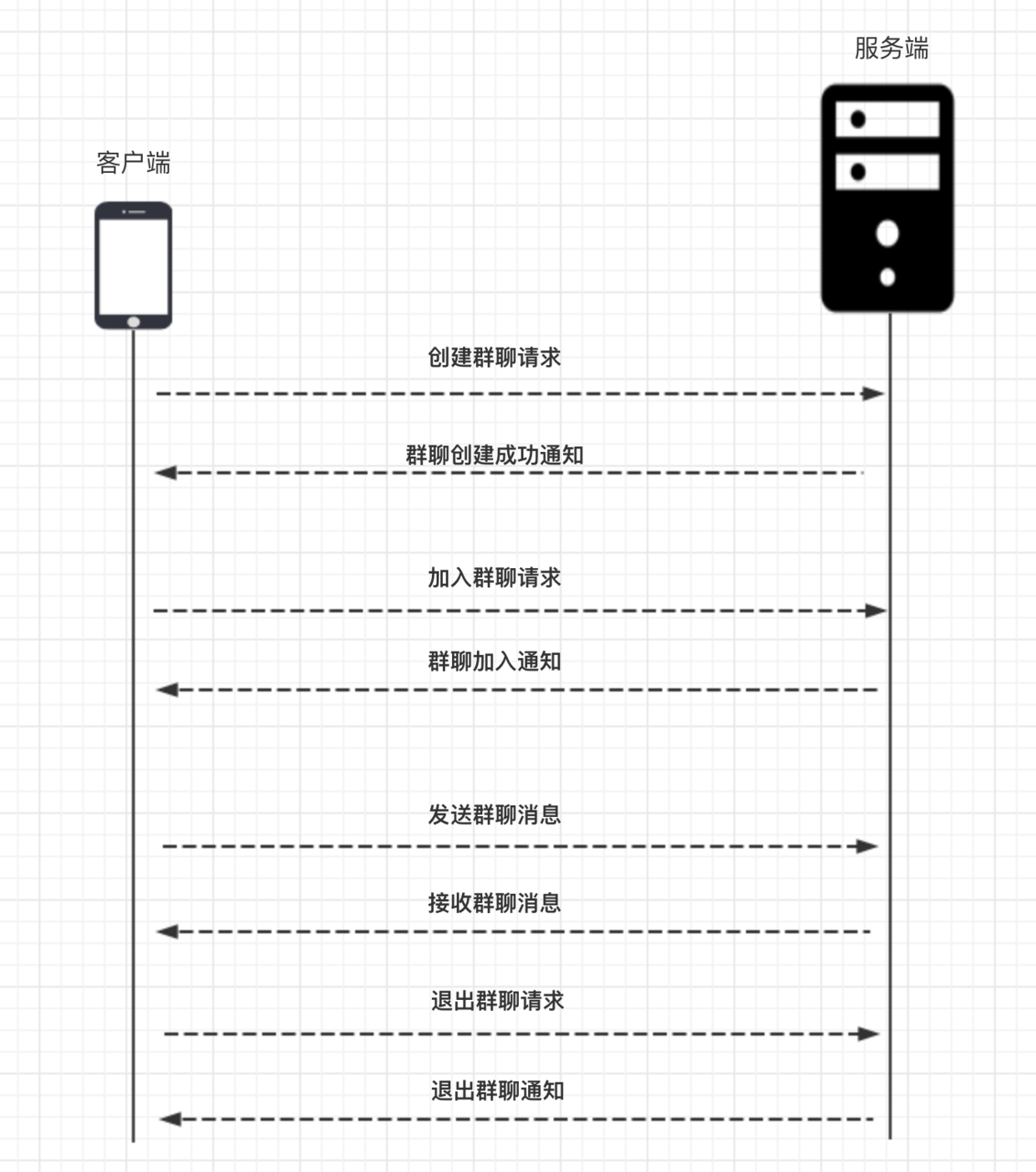
群聊
基本流程
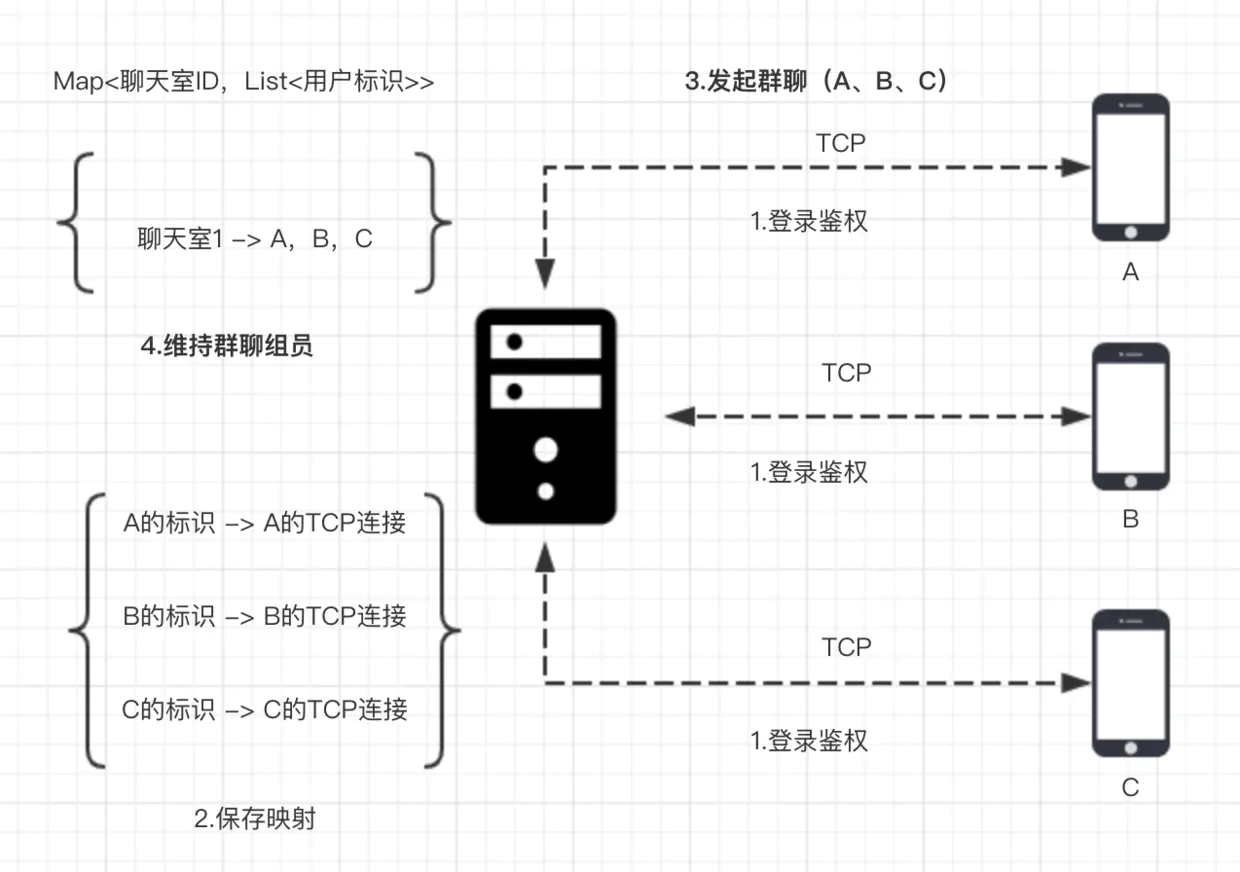
指令
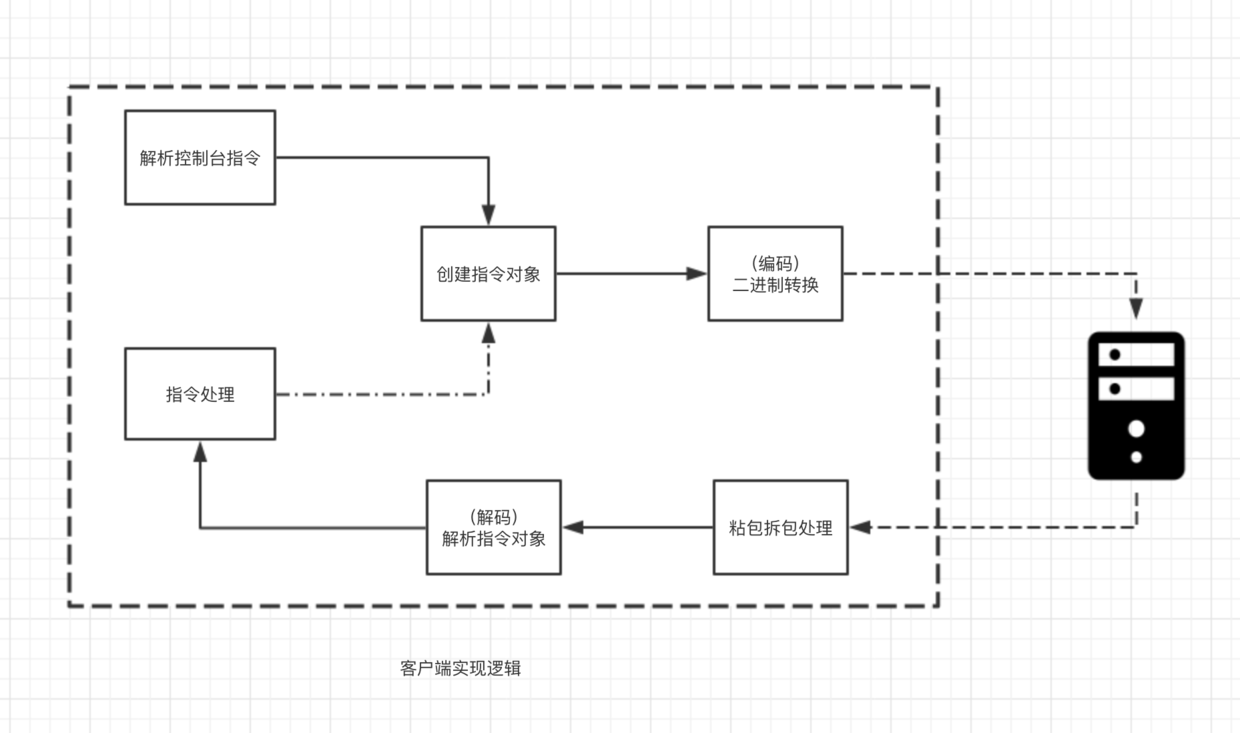
客户端使用 Netty 的程序逻辑结构
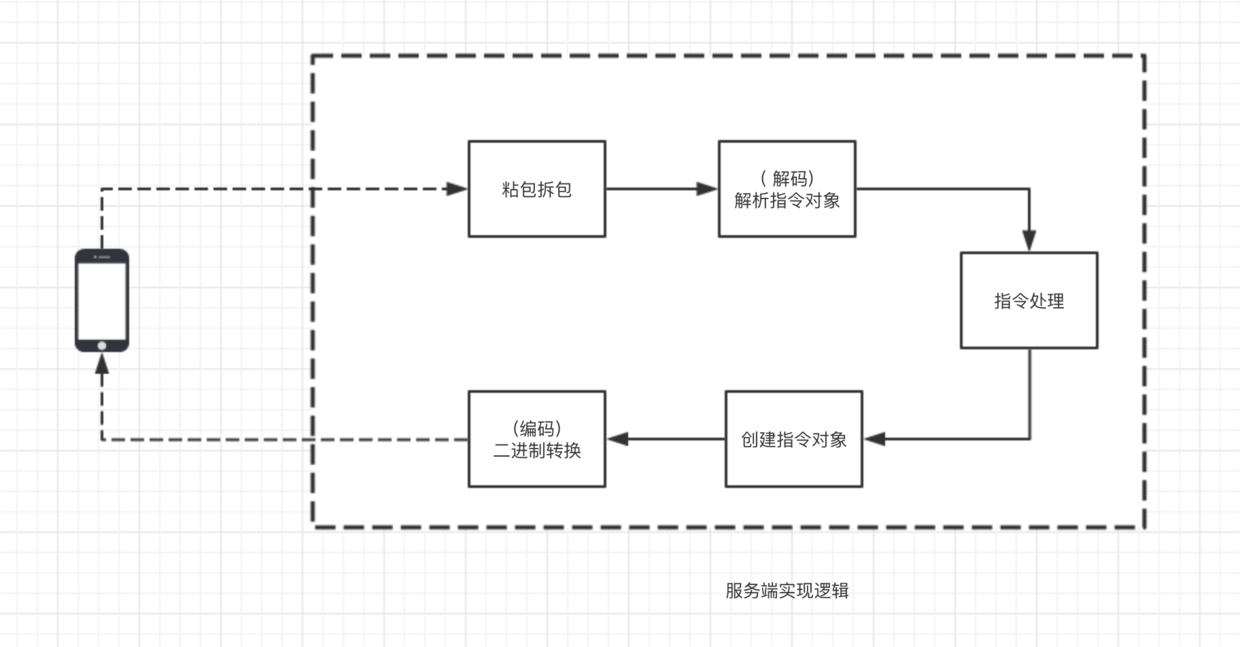
服务端使用 Netty 的程序逻辑结构
服务端启动流程
服务端启动demo
话不多说,直接上代码
NettyServer.java
1 | public class NettyServer { |
服务端启动其他方法
handler()方法
1 | serverBootstrap.handler(new ChannelInitializer<NioServerSocketChannel>() { |
handler()方法呢,可以和我们前面分析的childHandler()方法对应起来,childHandler()用于指定处理新连接数据的读写处理逻辑,handler()用于指定在服务端启动过程中的一些逻辑,通常情况下呢,我们用不着这个方法。
attr()方法
1 | serverBootstrap.attr(AttributeKey.newInstance("serverName"), "nettyServer") |
attr()方法可以给服务端的 channel,也就是NioServerSocketChannel指定一些自定义属性,然后我们可以通过channel.attr()取出这个属性,比如,上面的代码我们指定我们服务端channel的一个serverName属性,属性值为nettyServer,其实说白了就是给NioServerSocketChannel维护一个map而已,通常情况下,我们也用不上这个方法。
childAttr()方法
1 | serverBootstrap.childAttr(AttributeKey.newInstance("clientKey"), "clientValue") |
上面的childAttr可以给每一条连接指定自定义属性,然后后续我们可以通过channel.attr()取出该属性。
childOption()方法
1 | serverBootstrap |
childOption()可以给每条连接设置一些TCP底层相关的属性,比如上面,我们设置了两种TCP属性,其中
ChannelOption.SO_KEEPALIVE表示是否开启TCP底层心跳机制,true为开启ChannelOption.TCP_NODELAY表示是否开启Nagle算法,true表示关闭,false表示开启,通俗地说,如果要求高实时性,有数据发送时就马上发送,就关闭,如果需要减少发送次数减少网络交互,就开启。
option()方法
除了给每个连接设置这一系列属性之外,我们还可以给服务端channel设置一些属性,最常见的就是so_backlog,如下设置
1 | serverBootstrap.option(ChannelOption.SO_BACKLOG, 1024) |
表示系统用于临时存放已完成三次握手的请求的队列的最大长度,如果连接建立频繁,服务器处理创建新连接较慢,可以适当调大这个参数
总结
- 本文中,我们首先学习了 Netty 服务端启动的流程,一句话来说就是:创建一个引导类,然后给他指定线程模型,IO模型,连接读写处理逻辑,绑定端口之后,服务端就启动起来了。
- 然后,我们学习到 bind 方法是异步的,我们可以通过这个异步机制来实现端口递增绑定。
- 最后呢,我们讨论了 Netty 服务端启动额外的参数,主要包括给服务端 Channel 或者客户端 Channel 设置属性值,设置底层 TCP 参数。
客户端启动流程
客户端启动demo
1 | public class NettyClient { |
我们定时任务是调用 bootstrap.config().group().schedule(), 其中 bootstrap.config() 这个方法返回的是 BootstrapConfig,他是对 Bootstrap 配置参数的抽象,然后 bootstrap.config().group() 返回的就是我们在一开始的时候配置的线程模型 workerGroup,调 workerGroup 的 schedule 方法即可实现定时任务逻辑。
客户端启动其他方法
attr()方法
1 | bootstrap.attr(AttributeKey.newInstance("clientName"), "nettyClient") |
option()方法
1 | Bootstrap |
option()方法可以给连接设置一些 TCP 底层相关的属性,比如上面,我们设置了三种 TCP 属性,其中
ChannelOption.CONNECT_TIMEOUT_MILLIS表示连接的超时时间,超过这个时间还是建立不上的话则代表连接失败ChannelOption.SO_KEEPALIVE表示是否开启 TCP 底层心跳机制,true 为开启ChannelOption.TCP_NODELAY表示是否开始 Nagle 算法,true 表示关闭,false 表示开启,通俗地说,如果要求高实时性,有数据发送时就马上发送,就设置为 true 关闭,如果需要减少发送次数减少网络交互,就设置为 false 开启
总结
- 学习了 Netty 客户端启动的流程,一句话来说就是:创建一个引导类,然后给他指定线程模型,IO 模型,连接读写处理逻辑,连接上特定主机和端口,客户端就启动起来了。
- 学习到 connect 方法是异步的,我们可以通过这个异步回调机制来实现指数退避重连逻辑。
- 学习了 Netty 客户端启动额外的参数,主要包括给客户端 Channel 绑定自定义属性值,设置底层 TCP 参数。
实战:客户端与服务端双向通信
实现功能: 客户端连接成功之后,向服务端写一段数据 ,服务端收到数据之后打印,并向客户端回一段数据
客户端发数据到服务端
在initChannel()方法里面给客户端添加一个逻辑处理器,这个处理器的作用就是负责向服务端写数据
1 | bootstrap |
逻辑处理器相关的代码
1 | public class FirstClientHandler extends ChannelInboundHandlerAdapter { |
写数据的逻辑分为两步:首先我们需要获取一个 netty 对二进制数据的抽象 ByteBuf,上面代码中, ctx.alloc() 获取到一个 ByteBuf 的内存管理器,这个 内存管理器的作用就是分配一个 ByteBuf,然后我们把字符串的二进制数据填充到 ByteBuf,这样我们就获取到了 Netty 需要的一个数据格式,最后我们调用 ctx.channel().writeAndFlush() 把数据写到服务端。
Netty 里面数据是以 ByteBuf 为单位的, 所有需要写出读取的数据都必须塞到一个 ByteBuf
服务端读取客户端数据
在 initChannel() 方法里面给服务端添加一个逻辑处理器,这个处理器的作用就是负责读取客户端来的数据
1 | serverBootstrap |
逻辑处理器相关的代码
1 | public class FirstServerHandler extends ChannelInboundHandlerAdapter { |
先运行服务端再运行客户端,客户端成功写出数据,服务端成功读取数据。
实现了客户端发数据服务端打印
服务端回数据给客户端
服务端向客户端写数据逻辑与客户端侧的写数据逻辑一样,先创建一个 ByteBuf,然后填充二进制数据,最后调用 writeAndFlush() 方法写出去,下面是服务端回数据的代码
1 | public class FirstServerHandler extends ChannelInboundHandlerAdapter { |
客户端的读取数据的逻辑和服务端读取数据的逻辑一样,同样是覆盖 ChannelRead() 方法
1 |
|
到这里,我们本小节要实现的客户端与服务端双向通信的功能实现完毕
总结
- 本文中,我们了解到客户端和服务端的逻辑处理是均是在启动的时候,通过给逻辑处理链
pipeline添加逻辑处理器,来编写数据的读写逻辑,pipeline的逻辑我们在后面会分析。 - 接下来,我们学到,在客户端连接成功之后会回调到逻辑处理器的
channelActive()方法,而不管是服务端还是客户端,收到数据之后都会调用到channelRead方法。 - 写数据调用
writeAndFlush方法,客户端与服务端交互的二进制数据载体为ByteBuf,ByteBuf通过连接的内存管理器创建,字节数据填充到ByteBuf之后才能写到对端,接下来一小节,我们就来重点分析ByteBuf。
数据传输载体 ByteBuf 介绍
ByteBuf结构
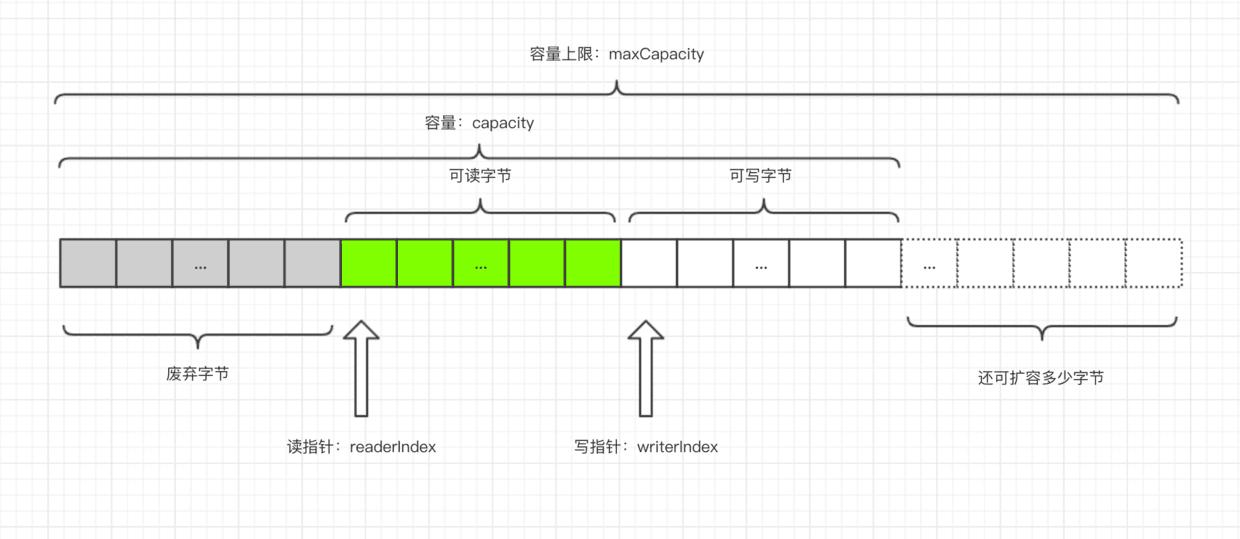
- ByteBuf 是一个字节容器,容器里面的的数据分为三个部分,第一个部分是已经丢弃的字节,这部分数据是无效的;第二部分是可读字节,这部分数据是 ByteBuf 的主体数据, 从 ByteBuf 里面读取的数据都来自这一部分;最后一部分的数据是可写字节,所有写到 ByteBuf 的数据都会写到这一段。最后一部分虚线表示的是该 ByteBuf 最多还能扩容多少容量
- 以上三段内容是被两个指针给划分出来的,从左到右,依次是读指针(readerIndex)、写指针(writerIndex),然后还有一个变量 capacity,表示 ByteBuf 底层内存的总容量
- 从 ByteBuf 中每读取一个字节,readerIndex 自增1,ByteBuf 里面总共有 writerIndex-readerIndex 个字节可读, 由此可以推论出当 readerIndex 与 writerIndex 相等的时候,ByteBuf 不可读
- 写数据是从 writerIndex 指向的部分开始写,每写一个字节,writerIndex 自增1,直到增到 capacity,这个时候,表示 ByteBuf 已经不可写了
B5. yteBuf 里面其实还有一个参数 maxCapacity,当向 ByteBuf 写数据的时候,如果容量不足,那么这个时候可以进行扩容,直到 capacity 扩容到 maxCapacity,超过 maxCapacity 就会报错
容量API
capacity()
表示 ByteBuf 底层占用了多少字节的内存
maxCapacity()
表示 ByteBuf 底层最大能够占用多少字节的内存
readableBytes() 与 isReadable()
readableBytes() 表示 ByteBuf 当前可读的字节数,它的值等于 writerIndex-readerIndex,如果两者相等,则不可读,isReadable() 方法返回 false
writableBytes()、 isWritable() 与 maxWritableBytes()
writableBytes() 表示 ByteBuf 当前可写的字节数,它的值等于 capacity-writerIndex,如果两者相等,则表示不可写,isWritable() 返回 false,但是这个时候,并不代表不能往 ByteBuf 中写数据了, 如果发现往 ByteBuf 中写数据写不进去的话,Netty 会自动扩容 ByteBuf,直到扩容到底层的内存大小为 maxCapacity,而 maxWritableBytes() 就表示可写的最大字节数,它的值等于 maxCapacity-writerIndex
读写指针相关的 API
readerIndex() 与 readerIndex(int)
前者表示返回当前的读指针 readerIndex, 后者表示设置读指针
writeIndex() 与 writeIndex(int)
前者表示返回当前的写指针 writerIndex, 后者表示设置写指针
markReaderIndex() 与 resetReaderIndex()
前者表示把当前的读指针保存起来,后者表示把当前的读指针恢复到之前保存的值
markWriterIndex() 与 resetWriterIndex()
同上
读写 API
writeBytes(byte[] src) 与 buffer.readBytes(byte[] dst)
writeBytes() 表示把字节数组 src 里面的数据全部写到 ByteBuf,而 readBytes() 指的是把 ByteBuf 里面的数据全部读取到 dst,这里 dst 字节数组的大小通常等于 readableBytes(),而 src 字节数组大小的长度通常小于等于 writableBytes()
writeByte(byte b) 与 buffer.readByte()
writeByte() 表示往 ByteBuf 中写一个字节,而 buffer.readByte() 表示从 ByteBuf 中读取一个字节,类似的 API 还有 writeBoolean()、writeChar()、writeShort()、writeInt()、writeLong()、writeFloat()、writeDouble() 与 readBoolean()、readChar()、readShort()、readInt()、readLong()、readFloat()、readDouble()
与读写 API 类似的 API 还有 getBytes、getByte() 与 setBytes()、setByte() 系列,唯一的区别就是 get/set 不会改变读写指针,而 read/write 会改变读写指针
release() 与 retain()
由于 Netty 使用了堆外内存,而堆外内存是不被 jvm 直接管理的,也就是说申请到的内存无法被垃圾回收器直接回收,所以需要我们手动回收。有点类似于c语言里面,申请到的内存必须手工释放,否则会造成内存泄漏。
Netty 的 ByteBuf 是通过引用计数的方式管理的,如果一个 ByteBuf 没有地方被引用到,需要回收底层内存。默认情况下,当创建完一个 ByteBuf,它的引用为1,然后每次调用 retain() 方法, 它的引用就加一, release() 方法原理是将引用计数减一,减完之后如果发现引用计数为0,则直接回收 ByteBuf 底层的内存。
slice()、duplicate()、copy()
这三个方法通常情况会放到一起比较,这三者的返回值都是一个新的 ByteBuf 对象
- slice() 方法从原始 ByteBuf 中截取一段,这段数据是从 readerIndex 到 writeIndex,同时,返回的新的 ByteBuf 的最大容量 maxCapacity 为原始 ByteBuf 的 readableBytes()
- duplicate() 方法把整个 ByteBuf 都截取出来,包括所有的数据,指针信息
- slice() 方法与 duplicate() 方法的相同点是:底层内存以及引用计数与原始的 ByteBuf 共享,也就是说经过 slice() 或者 duplicate() 返回的 ByteBuf 调用 write 系列方法都会影响到 原始的 ByteBuf,但是它们都维持着与原始 ByteBuf 相同的内存引用计数和不同的读写指针
- slice() 方法与 duplicate() 不同点就是:slice() 只截取从 readerIndex 到 writerIndex 之间的数据,它返回的 ByteBuf 的最大容量被限制到 原始 ByteBuf 的 readableBytes(), 而 duplicate() 是把整个 ByteBuf 都与原始的 ByteBuf 共享
- slice() 方法与 duplicate() 方法不会拷贝数据,它们只是通过改变读写指针来改变读写的行为,而最后一个方法 copy() 会直接从原始的 ByteBuf 中拷贝所有的信息,包括读写指针以及底层对应的数据,因此,往 copy() 返回的 ByteBuf 中写数据不会影响到原始的 ByteBuf
- slice() 和 duplicate() 不会改变 ByteBuf 的引用计数,所以原始的 ByteBuf 调用 release() 之后发现引用计数为零,就开始释放内存,调用这两个方法返回的 ByteBuf 也会被释放,这个时候如果再对它们进行读写,就会报错。因此,我们可以通过调用一次 retain() 方法 来增加引用,表示它们对应的底层的内存多了一次引用,引用计数为2,在释放内存的时候,需要调用两次 release() 方法,将引用计数降到零,才会释放内存
- 这三个方法均维护着自己的读写指针,与原始的 ByteBuf 的读写指针无关,相互之间不受影响
实战
ByteBufTest.java
1 | public class ByteBufTest { |
客户端与服务端通信协议编解码
服务端与客户端的通信协议
无论是使用 Netty 还是原始的 Socket 编程,基于 TCP 通信的数据包格式均为二进制,协议指的就是客户端与服务端事先商量好的,每一个二进制数据包中每一段字节分别代表什么含义的规则。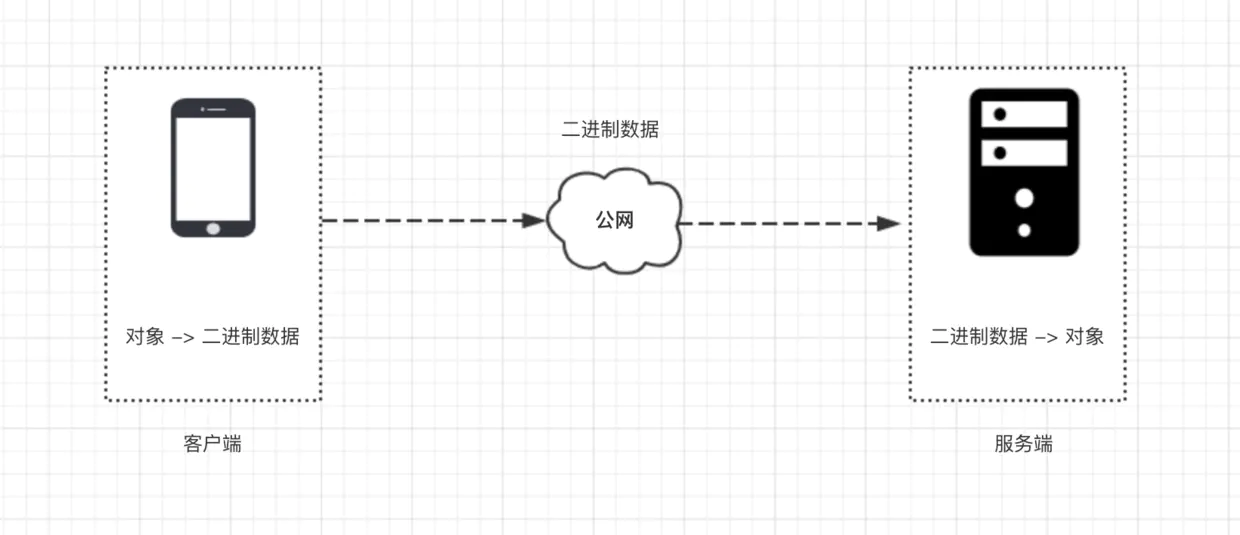
如上图所示,客户端与服务端通信
- 首先,客户端把一个 Java 对象按照通信协议转换成二进制数据包。
- 然后通过网络,把这段二进制数据包发送到服务端,数据的传输过程由 TCP/IP 协议负责数据的传输,与我们的应用层无关。
- 服务端接受到数据之后,按照协议取出二进制数据包中的相应字段,包装成 Java 对象,交给应用逻辑处理。
- 服务端处理完之后,如果需要吐出响应给客户端,那么按照相同的流程进行。
通信协议的设计

- 首先,第一个字段是魔数,通常情况下为固定的几个字节(我们这边规定为4个字节)。 为什么需要这个字段,而且还是一个固定的数?假设我们在服务器上开了一个端口,比如 80 端口,如果没有这个魔数,任何数据包传递到服务器,服务器都会根据自定义协议来进行处理,包括不符合自定义协议规范的数据包。例如,我们直接通过 http://服务器ip 来访问服务器(默认为 80 端口), 服务端收到的是一个标准的 HTTP 协议数据包,但是它仍然会按照事先约定好的协议来处理 HTTP 协议,显然,这是会解析出错的。而有了这个魔数之后,服务端首先取出前面四个字节进行比对,能够在第一时间识别出这个数据包并非是遵循自定义协议的,也就是无效数据包,为了安全考虑可以直接关闭连接以节省资源。在 Java 的字节码的二进制文件中,开头的 4 个字节为0xcafebabe 用来标识这是个字节码文件,亦是异曲同工之妙。
- 接下来一个字节为版本号,通常情况下是预留字段,用于协议升级的时候用到,有点类似 TCP 协议中的一个字段标识是 IPV4 协议还是 IPV6 协议,大多数情况下,这个字段是用不到的,不过为了协议能够支持升级,我们还是先留着。
- 第三部分,序列化算法表示如何把 Java 对象转换二进制数据以及二进制数据如何转换回 Java 对象,比如 Java 自带的序列化,json,hessian 等序列化方式。
- 第四部分的字段表示指令,关于指令相关的介绍,我们在前面已经讨论过,服务端或者客户端每收到一种指令都会有相应的处理逻辑,这里,我们用一个字节来表示,最高支持256种指令,对于我们这个 IM 系统来说已经完全足够了。
- 接下来的字段为数据部分的长度,占四个字节。
- 最后一个部分为数据内容,每一种指令对应的数据是不一样的,比如登录的时候需要用户名密码,收消息的时候需要用户标识和具体消息内容等等。
通信协议的实现
把 Java 对象根据协议封装成二进制数据包的过程成为编码,而把从二进制数据包中解析出 Java 对象的过程成为解码,在使用 Netty 进行通信协议的编解码之前,我们先来定义一下客户端与服务端通信的 Java 对象。
java对象
首先定义通信过程中的java对象
1 |
|
以上是通信过程中 Java 对象的抽象类,定义了一个版本号(默认值为 1 )以及一个获取指令的抽象方法,所有的指令数据包都必须实现这个方法,这样就可以知道某种指令的含义。
@Data注解由 lombok 提供,它会自动帮我们生产 getter/setter 方法,减少大量重复代码,推荐使用。
拿客户端登录请求为例,定义登录请求数据包
1 |
|
登录请求数据包继承自 Packet,然后定义了三个字段,分别是用户 ID,用户名,密码,这里最为重要的就是覆盖了父类的 getCommand() 方法,值为常量 LOGIN_REQUEST。
序列化
把一个 Java 对象转换成二进制数据,这个规则叫做 Java 对象的序列化。
如下定义序列化接口
1 | public interface Serializer { |
序列化接口有三个方法,getSerializerAlgorithm() 获取具体的序列化算法标识,serialize() 将 Java 对象转换成字节数组,deserialize() 将字节数组转换成某种类型的 Java 对象。本系统将使用最简单的 json 序列化方式,使用阿里巴巴的 fastjson 作为序列化框架。
1 | public class JSONSerializer implements Serializer { |
定义一下序列化算法的类型以及默认序列化算法
1 | public interface SerializerAlgorithm { |
这样就实现了序列化相关的逻辑,如果想要实现其他序列化算法的话,只需要继承一下 Serializer,然后定义一下序列化算法的标识,再覆盖一下两个方法即可。
编码:封装成二进制的过程
1 | public class PacketCodeC { |
编码过程分为三个过程
- 首先,我们需要创建一个 ByteBuf,这里我们调用 Netty 的 ByteBuf 分配器来创建,ioBuffer() 方法会返回适配 io 读写相关的内存,它会尽可能创建一个直接内存,直接内存可以理解为不受 jvm 堆管理的内存空间,写到 IO 缓冲区的效果更高。
- 接下来,我们将 Java 对象序列化成二进制数据包。
- 最后,对照本小节开头协议的设计以及上一小节 ByteBuf 的 API,逐个往 ByteBuf 写入字段,即实现了编码过程,到此,编码过程结束。
一端实现了编码之后,Netty 会将此 ByteBuf 写到另外一端,另外一端拿到的也是一个 ByteBuf 对象,基于这个 ByteBuf 对象,就可以反解出在对端创建的 Java 对象,这个过程我们称作为解码
解码:解析Java对象的过程
1 | /** |
解码的流程如下:
- 我们假定 decode 方法传递进来的 ByteBuf 已经是合法的(在后面小节我们再来实现校验),即首四个字节是我们前面定义的魔数 0x12345678,这里我们调用 skipBytes 跳过这四个字节。
- 这里,我们暂时不关注协议版本,通常我们在没有遇到协议升级的时候,这个字段暂时不处理,因为,你会发现,绝大多数情况下,这个字段几乎用不着,但我们仍然需要暂时留着。
- 接下来,我们调用 ByteBuf 的 API 分别拿到序列化算法标识、指令、数据包的长度。
- 最后,我们根据拿到的数据包的长度取出数据,通过指令拿到该数据包对应的 Java 对象的类型,根据序列化算法标识拿到序列化对象,将字节数组转换为 Java 对象,至此,解码过程结束。
总结
知识点如下:
- 通信协议是为了服务端与客户端交互,双方协商出来的满足一定规则的二进制数据格式。
- 介绍了一种通用的通信协议的设计,包括魔数、版本号、序列化算法标识、指令、数据长度、数据几个字段,该协议能够满足绝大多数的通信场景。
- Java 对象以及序列化,目的就是实现 Java 对象与二进制数据的互转。
- 最后,我们依照我们设计的协议以及 ByteBuf 的 API 实现了通信协议,这个过程称为编解码过程。


